

How Meta trains large language models at scale
Engineering at Meta
JUNE 12, 2024
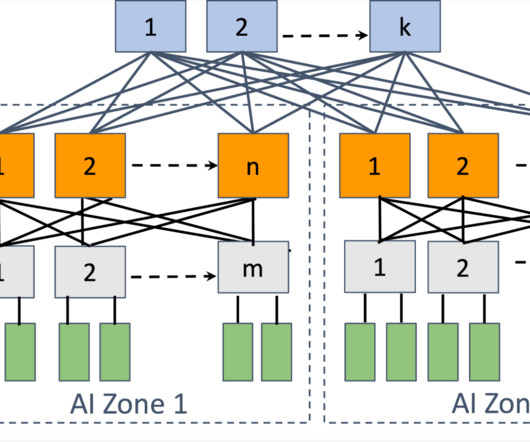
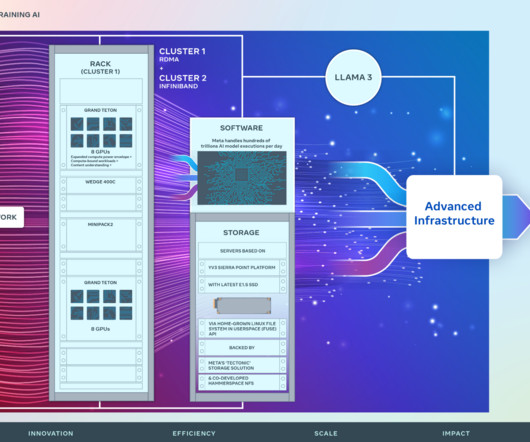
Optimal connectivity between GPUs: Large-scale model training involves transferring vast amounts of data between GPUs in a synchronized fashion. There are two leading choices in the industry that fit these requirements: RoCE and InfiniBand fabrics. A slow data exchange between a subset of GPUs can compound and slow down the whole job.


Let's personalize your content