
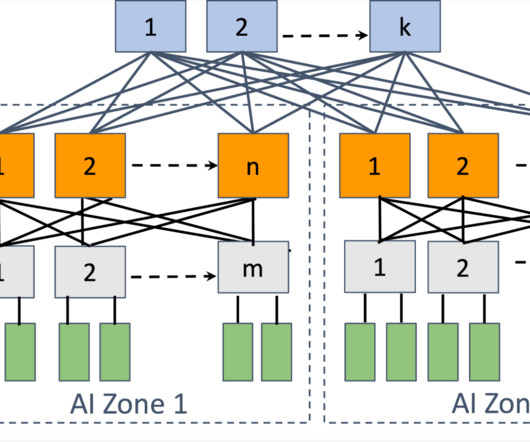
A RoCE network for distributed AI training at scale
Engineering at Meta
AUGUST 5, 2024
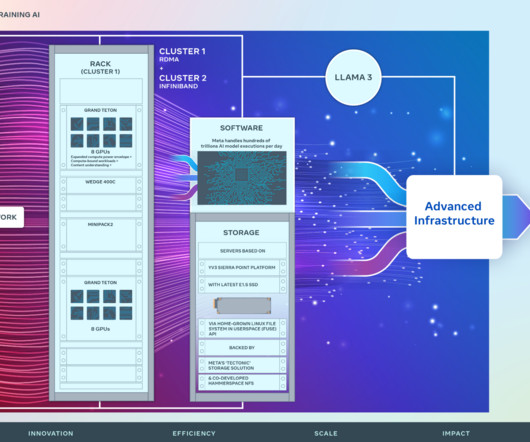
Distributed training, in particular, imposes the most significant strain on data center networking infrastructure. Constructing a reliable, high-performance network infrastructure capable of accommodating this burgeoning demand necessitates a reevaluation of data center network design.




Let's personalize your content