This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
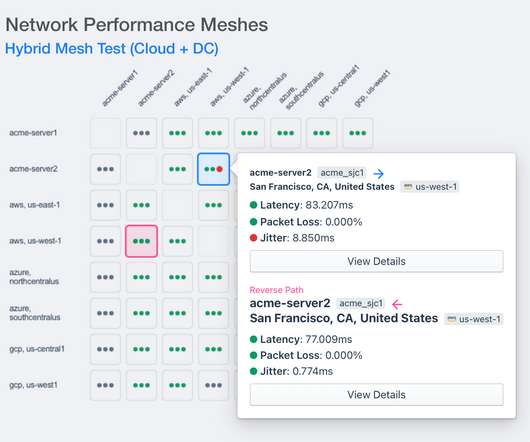
Occasionally, customers report issues such as high latency or not achieving their subscribed bandwidth. To address these concerns, we certify the last-mile connection using iPerf3 for traffic and bandwidth analysis. Attached is a topology diagram illustrating the proposed setup.
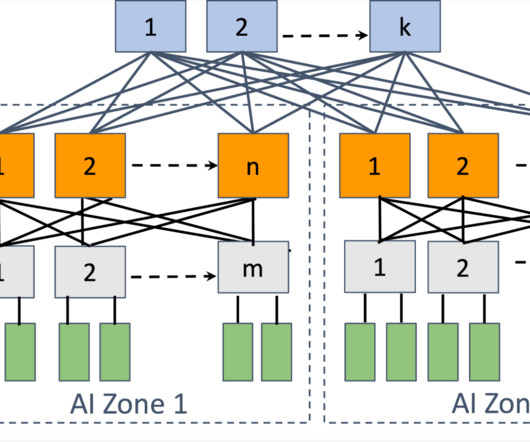
Topology We built a dedicated backend network specifically for distributed training. To support large language models (LLMs), we expanded the backend network towards the DC-scale, e.g., incorporating topology-awareness into the training job scheduler. We designed a two-stage Clos topology for AI racks, known as an AI Zone.
OSPF) maintain a map of the network topology and share updates only when changes occur, leading to faster convergence times. QoS ensures that critical applications receive the necessary bandwidth by prioritizing traffic. Techniques include traffic classification, queuing mechanisms, bandwidth reservation, and congestion management.
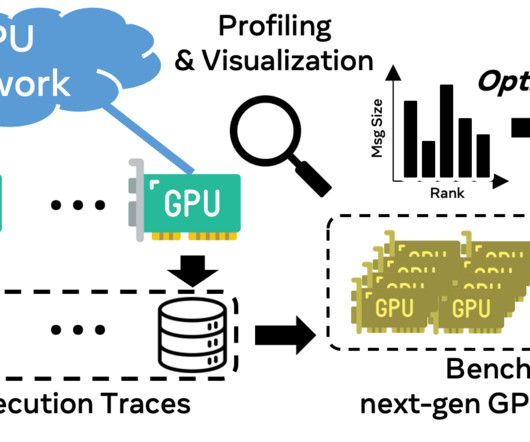
Such predictions become even more complex when the compute engines aren’t ready or when changes in network topology and bandwidth become necessary. As a result, traces sourced from one system might not accurately simulate on another with a different GPU, network topology, and bandwidth.
Not as difficult as time travel, but it’s difficult enough so that for 30+ years IT professionals have tried to skirt the issue by adding more bandwidth between locations or by rolling out faster routers and switches. Over the last few decades network managers have focused on adding bandwidth and reducing the network outages.
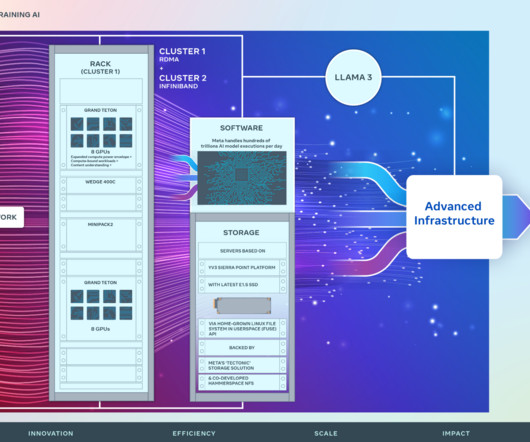
We optimized the RoCE cluster for quick build time, and the InfiniBand cluster for full-bisection bandwidth. We implemented collective communication patterns with network topology awareness so that they can be less latency-sensitive. Our intent was to build and learn from the operational experience.
Yes, there’s something to say about how applications are written, but on the public internet side, we’ve seen a decrease in latency, cost, and a massive increase in available bandwidth. This coincided with the advent of the public cloud like AWS, Azure, GCP, etc. Yes, of course, I’m oversimplifying here. I know there are always exceptions.
By collecting and analyzing network telemetry, including traffic flows, bandwidth usage, packet loss rates, and error rates, NetOps leverage monitoring to detect and diagnose potential bottlenecks, security threats, and other issues that can impact network reliability, often before end users even notice a problem.
In the graph below, AllGather collective performance is shown (as normalized bandwidth on a 0-100 scale) when a large number of GPUs are communicating with each other at message sizes where roofline performance is expected. This helped push our large clusters to achieve great and expected performance just as our small clusters.
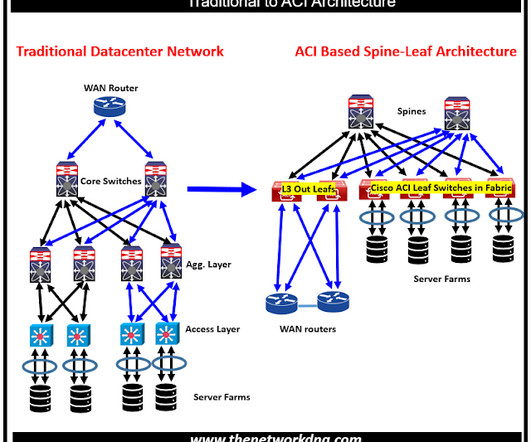
spine-leaf topologies provide excessive-bandwidth, low-latency, non-blocking server-to-server connectivity. Adding spine switches increases fabric bandwidth. Adding leaf switches increases end point bandwidth. Let's look at the top nine benefits and characteristics of ACI as compared to traditional networks.
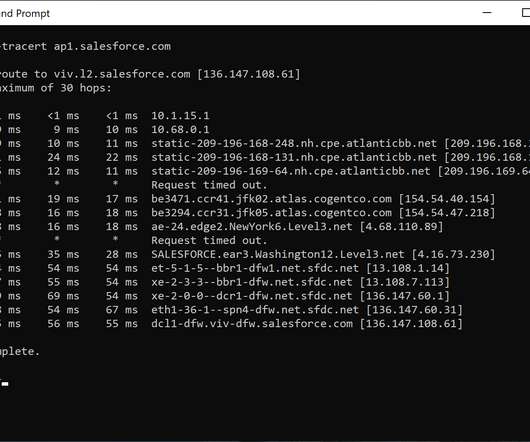
If you’re working from home, could it be possible that you’re competing with other local devices for that precious, limited bandwidth? For example, after thorough review of the traceroute and the BGP topology, a peering connection at the local IX could resolve the issue. Check your local network.
New Topology View and a New Backend The top-level topology view has been redesigned to accommodate deployments of thousands of sites and tens of thousands of users. We enhanced security reporting with an all-new threats dashboard and opened up application performance with another new dashboard.
Some of its limitations includes: Cost: MPLS connections are expensive and have hard caps on available bandwidth. If an organizations bandwidth needs exceed the current hardware capacity, new or additional hardware is required, and this can be a slow and expensive process.
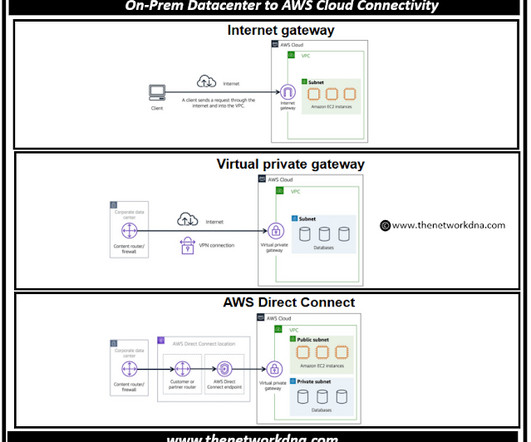
The private connection that AWS Direct Connect provides helps you to reduce network costs and increase the amount of bandwidth that can travel through your network. Continue Reading. Load balancers are important part of the Network ?
The problem is that as companies adopt cloud-based services, deploy more bandwidth-intensive applications, and connect an increasing number of devices and remote locations, business requirements change and new technical challenges arise. However, it comes with performance limitations and other challenges.
Why is my bandwidth bill so high? Commonly cited problems are a loss of visibility or understanding of the topology, loss of control over network policies (because developers can now create network constructs on their own), and new networking tools from the cloud providers that are often siloed and shallow in features.
This feature in networks predicts and stabilizes the topology. Low Overhead : Static routes do not consume bandwidth for routing updates or require additional CPU resources to compute paths. Disadvantages: Manual updates required for topology changes, not scalable for large networks, and risk of misconfiguration.
However, in order to operate a reliable stretch cluster, datacenters must be relatively close to each other and have a very stable, low latency, and high-bandwidth connection among the DCs. datacenter topology. This changes with the preview release of Confluent Platform 5.4, This is sometimes referred to as a 2.5
Why is my bandwidth bill so high? What users and applications are consuming my network bandwidth? The (typically static) configuration data representing the operating intent for all configurable network elements such as addresses, ID’s, ACLs, topology info, location data, even device details such as hardware and software versions.
That includes adding in high-value data such as threat feed and threat modeling, routing, topology, and other important networking information to model answers to difficult questions. Flow can also be used to understand consumption of bandwidth in a more granular manner.
That includes adding in high-value data such as threat feed and threat modeling, routing, topology, and other important networking information to model answers to difficult questions. Flow can also be used to understand consumption of bandwidth in a more granular manner.
Traditionally, enterprises configure their WAN in a classic hub-and-spoke topology, where users in sites access resources in headquarters or a datacenter. Bandwidth-intensive traffic, bound for the Internet and cloud, are backhauled across the MPLS WAN.
Youve been told to cut costs Its no secret that MPLS circuits cost a fortune often 3-4x the price of MPLS alternatives (like SD-WAN,) for only a fraction of the bandwidth. Get crystal clear on your WAN challenges: Do any of these challenges sound familiar? But the bottom line isnt the only factor to take into consideration.
To quickly resolve problems in either scenario, IT managers need new tools that can gain visibility into the end-to-end topology and various paths that traffic flows are traversing from the Internet breakout connection into multiple cloud provider networks.
Under this model, network topology is highly variable, creating a complexity that can mask root causes and make proactive availability configurations a highly brittle point of the network. Replication, analysis, and data transfer all present opportunities for security threats, data integrity loss, and intense bandwidth and memory consumption.
The mechanisms described above — such as the role placement algorithm — can only be effective when all of the participating entities are in agreement on the topology of the cluster together with the status and health of each node. For example, there is a mechanism to manage the relocation of roles when the topology changes.
Using the old approach to support the new needs results in expensive global connectivity, complex topologies and widely dispersed point products that are difficult to maintain and secure. SD-WANs reduce bandwidth costs by leveraging inexpensive services, such as Internet broadband, whenever possible. What are the Benefits of SD-WANs?
Note that enterprise topologies that have all sites close or all on a single access carrier may not have this exposure to the core Internet. However, in the event of network issues or congestion, mechanisms to allocate the available reduced bandwidth for optimal business value are critical. One area is identity.
Team Topologies approach to organizing software engineering teams has emerged as a great reference for building an effective platform engineering team. Click here to see the consolidated list of tools & technologies.
The diagram below illustrates the topology of the internet of Afghanistan based on BGP data from 10 years ago. Six ASNs represented its domestic internet with international bandwidth coming from either satellite providers or its neighboring countries, Pakistan, Tajikistan, Uzbekistan and Iran.
Cyberthreat strategies have evolved in step with modern cloud networks, often using cheap, virtualized cloud resources to exploit the threat surface topology I briefly described above. These attacks aim to overwhelm a service’s bandwidth capabilities with prohibitively high traffic volumes. Protocol-based.
MySQL Raft replication topologies A Raft ring would consist of several MySQL instances (four in the diagram) in different regions. Once in a while, automation could also change the regional placement of MySQL topology. The communication round-trip time (RTT) between these regions would range from 10 to 100 milliseconds.
Predictive energy utilization with AI: Forecasting network utilization and implementing dynamic topology adaptation allows for predictive energy usage. This enables proactive topology adjustments, such as routing traffic through energy-efficient paths and consolidating network flows.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content