This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
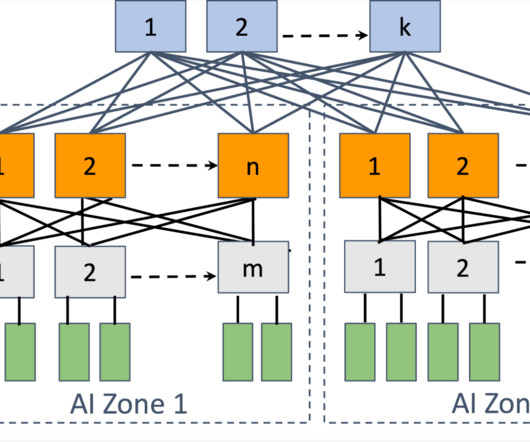
AI networks play an important role in interconnecting tens of thousands of GPUs together, forming the foundational infrastructure for training, enabling large models with hundreds of billions of parameters such as LLAMA 3.1 Distributed training, in particular, imposes the most significant strain on data center networking infrastructure.
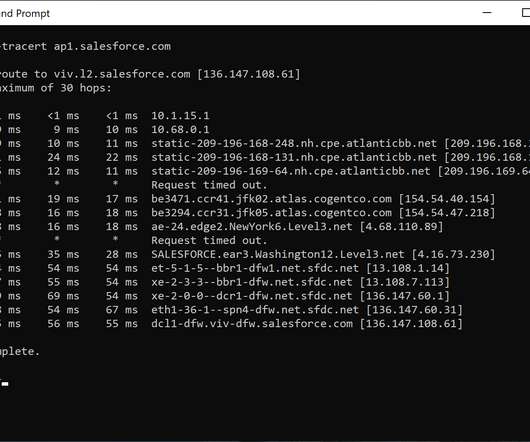
Occasionally, customers report issues such as high latency or not achieving their subscribed bandwidth. To address these concerns, we certify the last-mile connection using iPerf3 for traffic and bandwidth analysis. Attached is a topology diagram illustrating the proposed setup.
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? It’s often taken for granted by network specialists that there is a trade-off among these three facets. Durability.
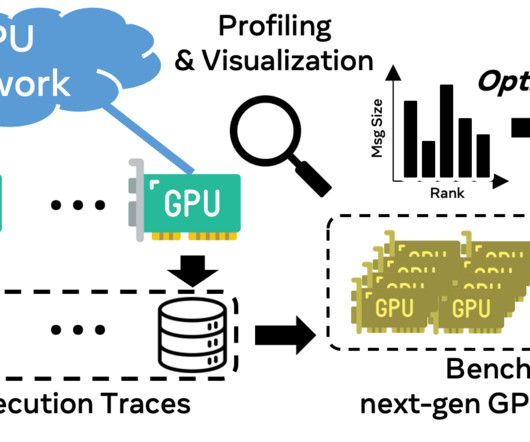
Meta presents Chakra execution traces , an open graph-based representation of AI/ML workload execution, laying the foundation for benchmarking and network performance optimization. At Meta, our endeavors are not only geared towards pushing the boundaries of AI/ML but also towards optimizing the vast networks that enable these computations.
Official Juniper Networks Blogs Sustainable Networks: powering the future, responsibly Imagine a data center humming with 100,000 cutting-edge GPUs, the backbone of the AI/ML and Gen AI revolution. Though reliable, this approach is increasingly at odds with todays sustainability goals.
As we progress into 2025, the landscape of networking continues to evolve rapidly, with new technologies, protocols, and security measures shaping the way organizations design and manage their networks. CCNA Interview Questions The CCNA certification serves as a foundational credential for network engineers.
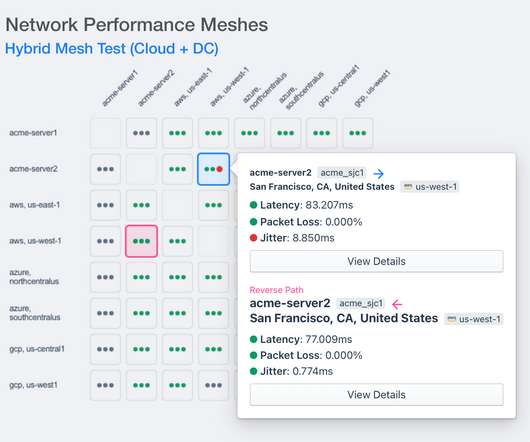
If you haven’t yet heard the term “network observability,” you will be hearing it soon. Some say that network observability is just marketing hype from vendors. They say, “networks have always been observable, so there’s nothing new here.” I say network observability is not just vendor hype, and this blog will make the case.
Latency is not a new problem in networking. Not as difficult as time travel, but it’s difficult enough so that for 30+ years IT professionals have tried to skirt the issue by adding more bandwidth between locations or by rolling out faster routers and switches. Fast forward to today, most networks enjoy five nines (99.999%) of uptime.
As networks become distributed and virtualized, the points at which they can be made vulnerable, or their threat surface , expands dramatically. This is compounded by recent trends of remote work, where network operators need to wrestle with the fact that employees often access the network via work sites with far less governance.
Supporting GenAI at scale has meant rethinking how our software, hardware, and network infrastructure come together. Solving this problem requires a robust and high-speed network infrastructure as well as efficient data transfer protocols and algorithms. requires revisiting trade-offs made for other types of workloads.
In part 2 of this series, I talked about the range of network devices and observation points that generate telemetry data. Over time, this range has expanded, and networks are more diverse than ever. Why is my bandwidth bill so high? What users and applications are consuming my networkbandwidth? Telemetry Types.
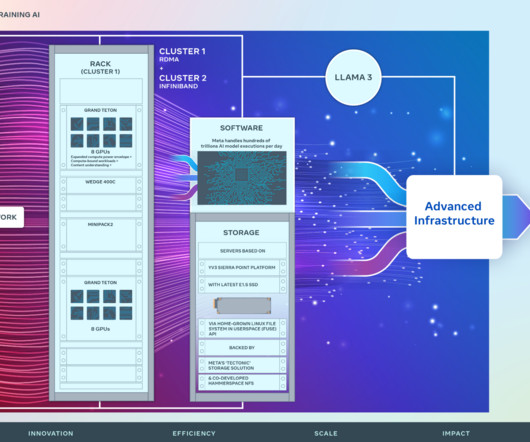
We are sharing details on the hardware, network, storage, design, performance, and software that help us extract high throughput and reliability for various AI workloads. Network At Meta, we handle hundreds of trillions of AI model executions per day. We use this cluster design for Llama 3 training.
Whether it’s as simple as ensuring solid connectivity with a SaaS provider or designing a robust, secure, hybrid, and multi-cloud architecture, the enterprise wide area network is all about connecting us to our resources, wherever they are. So what does this mean for today’s enterprise network engineer?
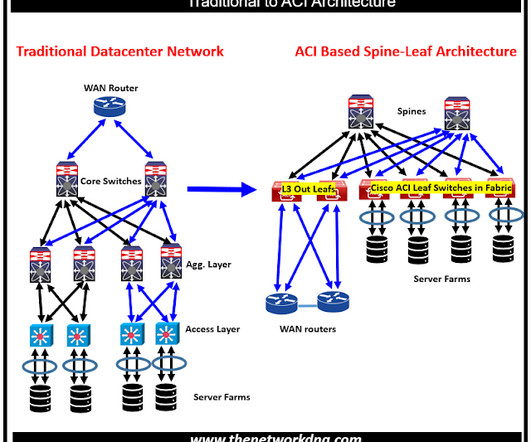
Why is Cisco ACI replacing traditional networks? Companies are increasingly moving from traditional networks to SDN-based networks. spine-leaf topologies provide excessive-bandwidth, low-latency, non-blocking server-to-server connectivity. Why is Cisco ACI replacing traditional networks? What is Cisco ACI ?
In the first part of this series , I introduced network reliability as a concept foundational to success for IT and business operations. I also pointed out that because of necessary factors like redundancy, the pursuit of reliability will inevitably mean making compromises that affect a network’s cost or performance.
There is a lot of confusion regarding the two primary data sets in network management: SNMP and flow. SNMP is used to collect metadata and metrics about a network device. This critical technology is a basic building block of modeling, measuring, and understanding the network. What is SNMP? What is Flow? When is SNMP Used?
Check your local network. If you’re working from home, could it be possible that you’re competing with other local devices for that precious, limited bandwidth? excessive browser extensions, unknown devices on your network, patches that should be applied, etc.). The problem may not be yours to solve.
There is a lot of confusion regarding the two primary data sets in network management: SNMP and flow. SNMP is used to collect metadata and metrics about a network device. This critical technology is a basic building block of modeling, measuring, and understanding the network. What is SNMP? What is Flow? When is SNMP Used?
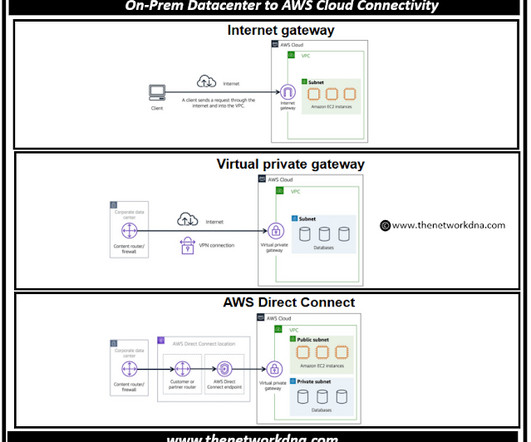
On-Prem Datacenter to AWS Cloud Connectivity Amazon Virtual Private Cloud (Amazon VPC) is a networking solution that allows you to set boundaries around your AWS resources. This isolated area allows you to launch resources in a virtual network that you have defined. Load balancers are important part of the Network ?
The WAN needs to offer high-performance and reliable network connectivity to ensure all users and applications can communicate effectively. These WAN routers defined the network boundaries and routed traffic to the appropriate destination. This allows the use of public internet for transport, which reduces networking costs.
Static routes are fundamental components in networking that help direct traffic efficiently from one network segment to another. We will also delve into practical examples and scenarios where static routing is preferred, giving you a thorough understanding of this essential networking concept. What is a Static Route?
That means making sure the wide area network (WAN) that connects branch offices, data centers, cloud services and SaaS applications can handle the connectivity needs of digitally empowered global organizations. Multiprotocol label switching protocol (MPLS) based networks, can no longer answer the business needs of a global enterprise.
However, in order to operate a reliable stretch cluster, datacenters must be relatively close to each other and have a very stable, low latency, and high-bandwidth connection among the DCs. In a multi-datacenter cluster, network ingress and egress can be very costly—certainly more costly than network traffic within a datacenter.
New Topology View and a New Backend The top-level topology view has been redesigned to accommodate deployments of thousands of sites and tens of thousands of users. Figure 1 Catos new Management Application lets enterprises continue to manage their network, security, and access infrastructure from a common interface (1).
Maybe youre an IT manager or a network engineer. Youve been told to cut costs Its no secret that MPLS circuits cost a fortune often 3-4x the price of MPLS alternatives (like SD-WAN,) for only a fraction of the bandwidth. Its about a year before your MPLS contract expires, and youve been told to cut costs by your CFO.
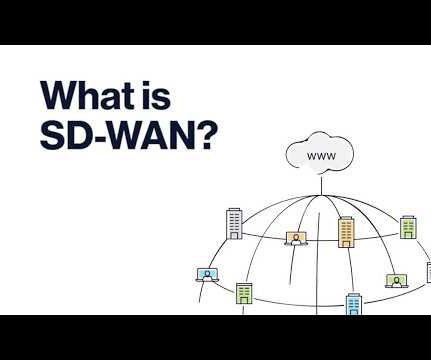
No longer an emerging technology, cloud computing is now used in everything from applications, storage, and networking. SD-WAN is used to connect enterprise networks over large geographic distances more efficiently across any available data transport, such as MPLS, LTE, or broadband.
SD-WANs are the confluence of four technology trends: software-defined networking in wide area networks (WANs), commodity hardware for customer premise equipment, Internet connectivity for business applications, and enterprise IT hybrid multi-cloud migration. The benefits of SD-WANs are compelling both economically and operationally.
This means that corporate networks must change as well. The answer Software-Defined Wide Area Networks (SD-WANs). SD-WAN brings unparalleled agility and cost savings to networking. SD-WAN does this by separating applications from the underlying network services with a policy-based, virtual overlay. How Does SD-WAN Work?
The mechanisms described above — such as the role placement algorithm — can only be effective when all of the participating entities are in agreement on the topology of the cluster together with the status and health of each node. For example, there is a mechanism to manage the relocation of roles when the topology changes.
Team Topologies approach to organizing software engineering teams has emerged as a great reference for building an effective platform engineering team. Click here to see the consolidated list of tools & technologies.
MySQL Raft replication topologies A Raft ring would consist of several MySQL instances (four in the diagram) in different regions. Once in a while, automation could also change the regional placement of MySQL topology. The communication round-trip time (RTT) between these regions would range from 10 to 100 milliseconds.
These solutions rely on the Internet, MPLS, or some other third-party network for connecting locations. These solutions can use MPLS in hybrid configurations, but they also bring a private interconnect their own network of Points of Presence (POPs) that manages the traffic flow across the middle-mile.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content