This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ethernet competes with InfiniBand as a network fabric for AI workloads such as model training. And while Ethernet has kept up with increasing demands to support greater bandwidth and throughput, it was. Read more » Ethernet competes with InfiniBand as a network fabric for AI workloads such as model training.
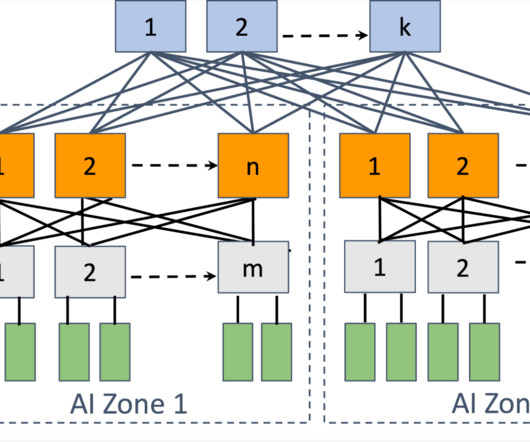
There are two leading choices in the industry that fit these requirements: RoCE and InfiniBand fabrics. On the other hand, Meta had built research clusters with InfiniBand as large as 16K GPUs. So we decided to build both: two 24k clusters , one with RoCE and another with InfiniBand. Both of these options had tradeoffs.
We discuss key considerations including bandwidth, the substantial power and cooling requirements of AI infrastructure, and GPUs. We also talk about InfiniBand and Ethernet as network fabrics for AI workloads, cabling considerations, and more. This is a sponsored episode. This is a sponsored episode.
We ensure that there is enough ingress bandwidth on the rack switch to not hinder the training workload. The BE is a specialized fabric that connects all RDMA NICs in a non-blocking architecture, providing high bandwidth, low latency, and lossless transport between any two GPUs in the cluster, regardless of their physical location.
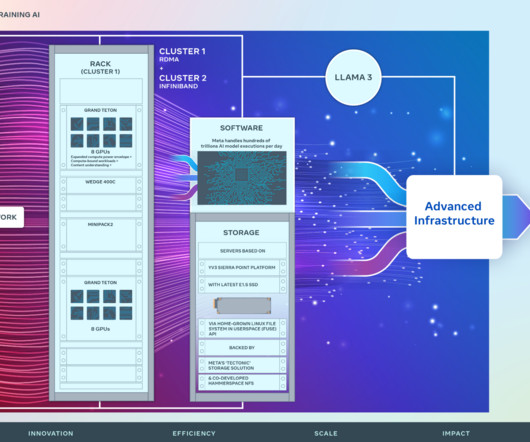
The other cluster features an NVIDIA Quantum2 InfiniBand fabric. Through careful co-design of the network, software, and model architectures, we have successfully used both RoCE and InfiniBand clusters for large, GenAI workloads (including our ongoing training of Llama 3 on our RoCE cluster) without any network bottlenecks.
In today’s high-speed networking world, optimizing and troubleshooting performance is crucial, especially with high-performance equipment like NVIDIA Infiniband switches. In this blog, we’ll share top tips for debugging and optimizing NVIDIA Infiniband networking performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







Let's personalize your content