
A RoCE network for distributed AI training at scale
Engineering at Meta
AUGUST 5, 2024
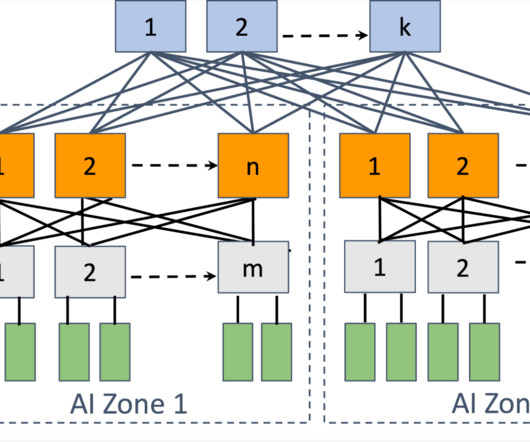
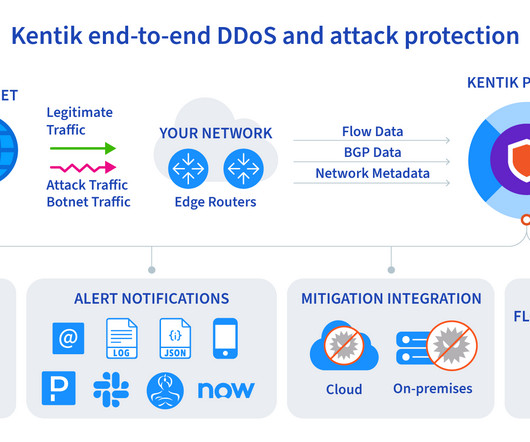
Topology We built a dedicated backend network specifically for distributed training. To support large language models (LLMs), we expanded the backend network towards the DC-scale, e.g., incorporating topology-awareness into the training job scheduler. We designed a two-stage Clos topology for AI racks, known as an AI Zone.















Let's personalize your content