

How Meta trains large language models at scale
Engineering at Meta
JUNE 12, 2024
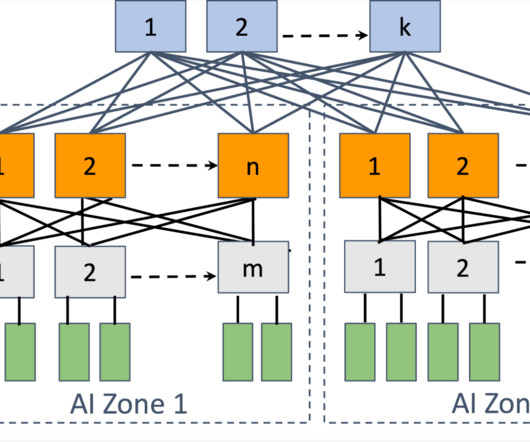
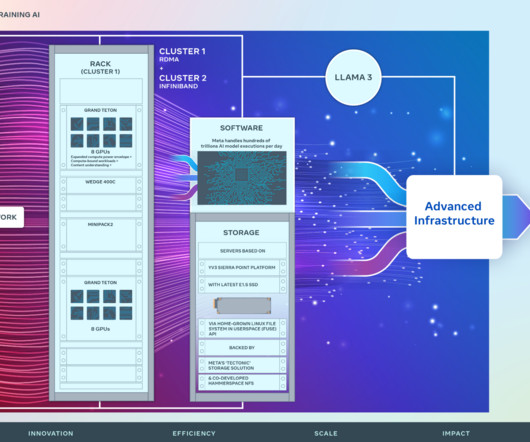
There are two leading choices in the industry that fit these requirements: RoCE and InfiniBand fabrics. On the other hand, Meta had built research clusters with InfiniBand as large as 16K GPUs. So we decided to build both: two 24k clusters , one with RoCE and another with InfiniBand. Both of these options had tradeoffs.



Let's personalize your content