This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Background As a platform engineer at a mid-size startup, Im responsible for identifying bottlenecks and developing solutions to streamline engineering operations to keep up with the velocity and scale of the engineering organization. Neal has more than ten years of experience developing software and is a Docker Captain.
Maintaining a strong security posture is challenging, especially with Linux. An effective approach is proactive and includes patch management, optimized resource allocation, and effective alerting. By Prashanth Ravula
Retrieval-Augmented-Generation (RAG) has quickly emerged as a powerful way to incorporate proprietary, real-time data into Large Language Model (LLM) applications. Today we are.
Speaker: Anindo Banerjea, CTO at Civio & Tony Karrer, CTO at Aggregage
When developing a Gen AI application, one of the most significant challenges is improving accuracy. 💥 Anindo Banerjea is here to showcase his significant experience building AI/ML SaaS applications as he walks us through the current problems his company, Civio, is solving. .
Operational Efficiency and Metrics Improvements: Traditional network metrics such as packet loss and jitter are too specific to the network/host and do not provide correlation between the application behavior and network performance.
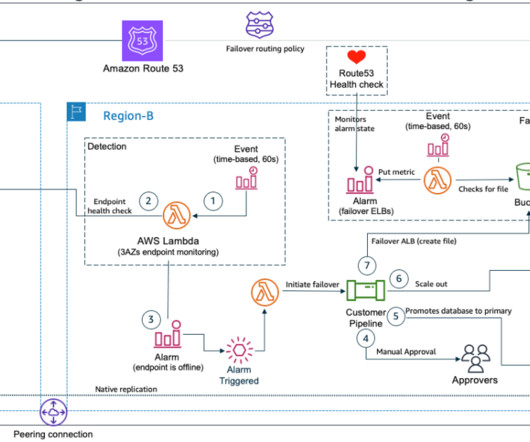
In this post, we explore how one of our customers, a US-based insurance company, uses cloud-native services to implement the disaster recovery of 3-tier applications. At this insurance company, a relevant number of critical applications are 3-tier Java or.Net applications.
They are used in internet search engines, social networks, WiFi, cell phones, and even satellites. Steps 6 - 8: The payment service (gRPC server) receives the packets from the network, decodes them, and invokes the server application. Over to you: Have you used gPRC in your project? What are some of its limitations? What is Docker ?
5 ⭐ on G2 Schedule a demo to learn more Disclaimer: The details in this post have been derived from Amazon Engineering Blog and other sources. All credit for the technical details goes to the Amazon engineering team. All credit for the technical details goes to the Amazon engineering team.
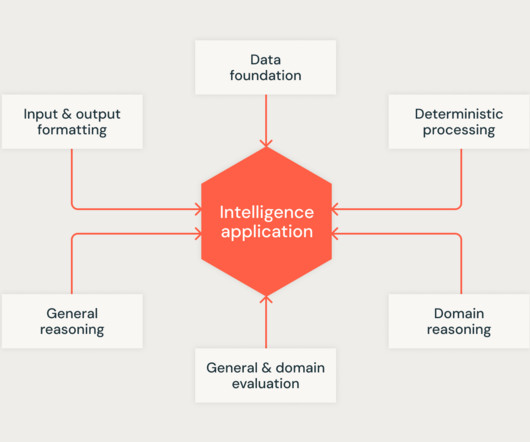
Technology professionals developing generative AI applications are finding that there are big leaps from POCs and MVPs to production-ready applications. However, during development – and even more so once deployed to production – best practices for operating and improving generative AI applications are less understood.
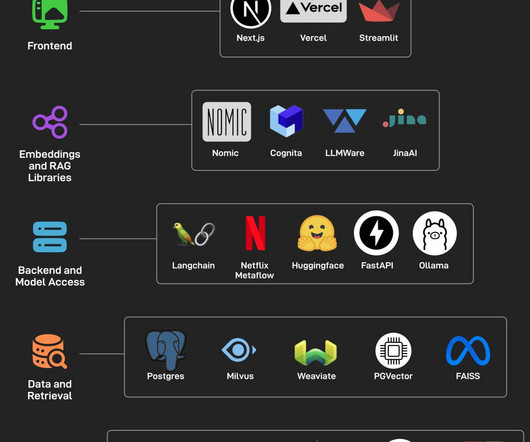
The Open Source AI Stack You don’t need to spend a fortune to build an AI application. Cookies Vs Sessions Vs JWT Vs PASETO Authentication ensures that only authorized users gain access to an application’s resources. Sessions are ideal for applications requiring strict server-side control over user data.
Essentials for 2025, including CCNA training, cybersecurity fundamentals, programming for network engineers, application development, and SD-WAN operations. Discover the top five Learning Paths in Cisco U.
Engineers from the University of Glasgow are teaming up with colleagues from the Tyndall National Institutes Wireless Communications Laboratory (WCL) for the project, called Active intelligent Reconfigurable surfaces for 6G wireless COMmunications (or AR-COM). AR-COM will move through four key stages of research and development.
Speaker: Maher Hanafi, VP of Engineering at Betterworks & Tony Karrer, CTO at Aggregage
💡 This new webinar featuring Maher Hanafi, VP of Engineering at Betterworks, will explore a practical framework to transform Generative AI prototypes into impactful products! There's no question that it is challenging to figure out where to focus and how to advance when it’s a new field that is evolving everyday.
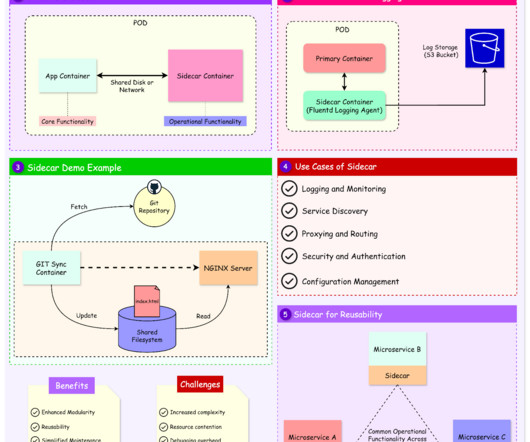
The sidecar pattern is one such design pattern that has gained prominence in modern software engineering. At its core, the sidecar pattern pairs a secondary process or service (the "sidecar") with a primary application to handle complementary tasks.
In this article, Senior Engineering Manager and AWS Serverless Hero Sheen Brisals examines how the characteristics of serverless such as optimization, robust availability and scalability influence us to think in a new way of architecting and evolving modern applications as set pieces, a concept from moviemaking.
In the InfoQ "Practical Applications of Generative AI" article series, we present real-world solutions and hands-on practices from leading GenAI practitioners. Generative AI (GenAI) has become a major component of the artificial intelligence (AI) and machine learning (ML) industry. However, using GenAI comes with challenges and risks.
By identifying and resolving inefficiencies early in the development lifecycle, software development teams can overcome common engineering challenges such as slow dev cycles, spiraling infrastructure costs, and scaling challenges. With Docker, applications behave predictably across every stage of the development lifecycle.
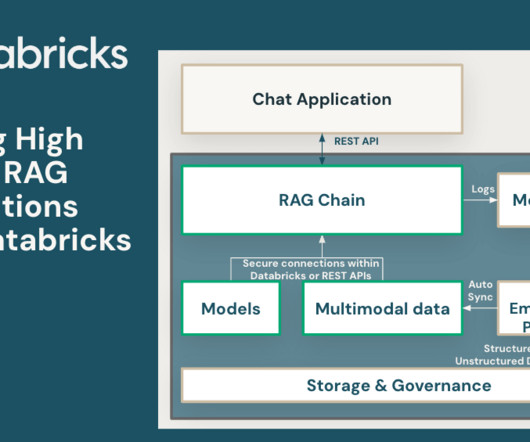
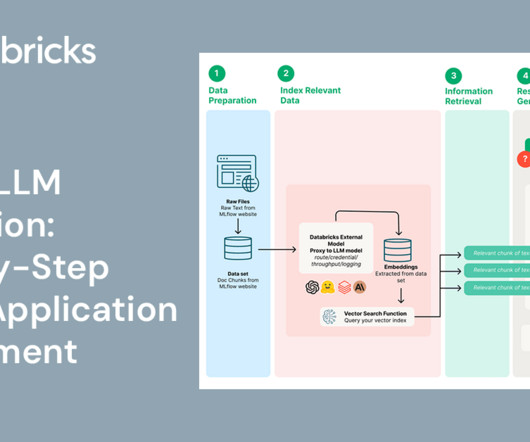
Background In an era where Retrieval-Augmented Generation (RAG) is revolutionizing the way we interact with AI-driven applications, ensuring the efficiency and effectiveness of.
While most engineering tooling at DoorDash is focused on making safe incremental improvements to existing systems, in part by testing in production (learn more about our end-to-end testing strategy ), this is not always the best approach when launching an entirely new business line. Set up a locally running containerized PostgreSQL database.
This fragmentation slows down innovation and makes it harder for teams to bring AI-driven features into their applications. Whether you’re developing cutting-edge AI/ML applications or just beginning to experiment with AI tools, this integration empowers developers to innovate without distraction. Docker Desktop 4.37
The key to developer velocity across AI lies in minimizing time to first batch (TTFB) for machine learning (ML) engineers. Time to first batch (TTFB), the delay from when a workflow is submitted to the training job’s first batch, plays an important role in accelerating our machine learning (ML) engineers’ iteration speeds.
We will walk through creating a Docker container for your Django application. Why containerize your Django application? WORKDIR : Sets the working directory of the application within the container. This change reduces the size of the image considerably, as the image now only contains what is needed to run the application.
In this article, author Ashley Davis discusses how to add a natural language interface to a chatbot application using OpenAI REST API. He also shows how to extend the chatbot by adding voice commands using MediaRecorder API and OpenAI's speech transcription API. By Ashley Davis
Chatbots are the most widely adopted use case for leveraging the powerful chat and reasoning capabilities of large language models (LLM). The retrieval.
Each benchmark within DCPerf is designed by referencing a large application within Meta’s production server fleet. DCPerf provides a much richer set of application software diversity and helps get better coverage signals on platform performance versus existing benchmarks such as SPEC CPU.
As a tech company, it’s our products and platform – and the engineers that build them – that power what DoorDash is able to offer our Consumers, Dashers, and Merchants every day. It’s for this reason that in Q2 2023, we revisited our performance expectations for all engineers at DoorDash.
Our engineers — the primary users of this platform — manage Kafka-related resources such as topics, users, and access control lists, or ACLs, through Terraform. Kafka Self-Serve empowers product engineers to onboard and manage their Kafka resources with minimal interaction from infrastructure engineers.
There are multiple strategies that can help: Containerization is one of the first strategies to make application deployments based on code. Docker is one of the most popular ways to containerize the application. Next, container orchestration becomes a necessity when dealing with multiple containers in an application.
The 2023 edition of Networking at Scale focused on how Meta’s engineers and researchers have been designing and operating the network infrastructure over the last several years for Meta’s AI workloads, including our numerous ranking and recommendation workloads and the immense GenAI models.
Finding good objects means identifying abstractions that are part of your applications domain and its execution machinery. Even when modeling domain concepts, you need to look carefully at how those objects fit into your overall application design. The alarm sounds, an engineer turns it off, but what happens to the second alarm?
This article is the last in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. When applying this to a dashboard application, the easiest way to use design effectively is to leverage existing patterns.
Open source is how we do modern software development, stitching together downloaded open-source libraries, frameworks, and other code to create new applications or functionality. Over the last 30 years, the world has become connected and digital. By Nithya Ruff
Operating critical Apache Kafka® event streaming applications in production requires sound automation and engineering practices. Streaming applications are often at the center of your transaction processing and data systems, requiring […].
This article details the enhanced capabilities of the open-source Llama 3 LLM, and how businesses can adopt the model in their applications. The author gives step-by-step instructions for deploying Llama 3 in the cloud or on-premise, and how to leverage fine-tuned versions for specific tasks. By Tingyi Li
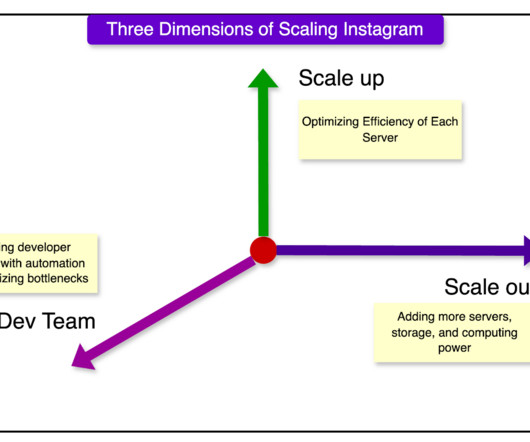
Register for Free Disclaimer: The details in this post have been derived from Instagram Engineering Blog and other sources. All credit for the technical details goes to the Instagram engineering team. Engineers would monitor CPU loads and decide if additional servers needed to be provisioned to handle the expected load.
Additionally, to meet and exceed our ambitions around AI leadership, its essential we tackle the skills gaps across several key areas connected to AI, including data centres and digital infrastructure, renewable power, sustainability, and engineering.
Successfully correlating monitoring and observability data to arrive allows engineers to arrive at the root cause more rapidly. Change Intelligence is often a missing component in incident management.
Downtime halts innovation as fines for compliance failures and engineering efforts re-route to forensic security analysis. This combination of tools enables your engineering team to put out fires and, more importantly, prevent them from starting in the first place. A breach is more than a line item in the budget.
Redpanda Streamfest: Learn the latest in streaming data and AI (Sponsored) Redpanda Streamfest is your best chance to learn the latest techniques and technologies for building data pipelines that support real-time applications, analytics and AI. Used in IPTV and video conference applications. The solution?
Systems and application logs play a key role in operations, observability, and debugging workflows at Meta. At a high level, Logarithm comprises the following components: Application processes emit logs using logging APIs. verbosity) in application code. learning rate), model internal state tensors (e.g., Multimodal data (e.g.,
Unlocking advertiser value through industry-leading ML innovation Meta Andromeda is a personalized ads retrieval engine that leverages the NVIDIA Grace Hopper Superchip, to enable cutting edge ML innovation in the Ads retrieval stage to drive efficiency and advertiser performance.
This experience brings a mature and proven approach, Vertiv tells us, providing data centre operators worldwide with expert support based on real-world application and success. The new Liquid Cooling Services offering is now globally available. For more from Vertiv, click here.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content