This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Also, the pivot to metaverse has led to a significant increase in AI, HPC, and machine learning workloads that demand huge networking bandwidth and compute capacity and pose challenges around safe co-existence of existing web, legacy and modern workloads.
5 ⭐ on G2 Schedule a demo to learn more Disclaimer: The details in this post have been derived from Amazon Engineering Blog and other sources. All credit for the technical details goes to the Amazon engineering team. All credit for the technical details goes to the Amazon engineering team.
Unlocking advertiser value through industry-leading ML innovation Meta Andromeda is a personalized ads retrieval engine that leverages the NVIDIA Grace Hopper Superchip, to enable cutting edge ML innovation in the Ads retrieval stage to drive efficiency and advertiser performance.
Register for Free Disclaimer: The details in this post have been derived from Instagram Engineering Blog and other sources. All credit for the technical details goes to the Instagram engineering team. Every media file must be optimized for different devices, ensuring smooth playback while minimizing bandwidth usage.
We ensure that there is enough ingress bandwidth on the rack switch to not hinder the training workload. The BE is a specialized fabric that connects all RDMA NICs in a non-blocking architecture, providing high bandwidth, low latency, and lossless transport between any two GPUs in the cluster, regardless of their physical location.
Internal tools are critical pieces of software, often custom-built, and requiring significant developer bandwidth. Low-code platforms can optimize developer productivity, facilitate collaboration, and allow less technical employees to be more active in the development process. By Nikhil Nandagopal.
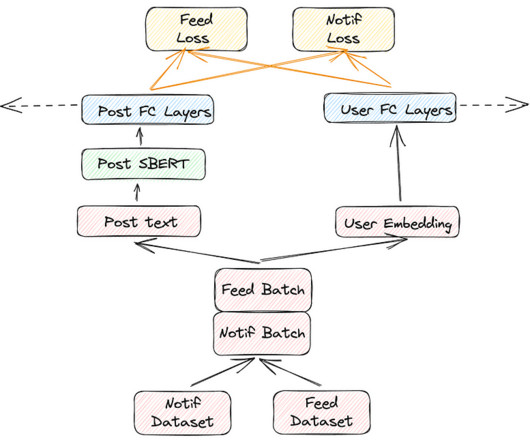
Systems and application logs play a key role in operations, observability, and debugging workflows at Meta. At a high level, Logarithm comprises the following components: Application processes emit logs using logging APIs. verbosity) in application code. learning rate), model internal state tensors (e.g., Multimodal data (e.g.,
In Catos Sales Engineers Demo and Interview Video Series , our sales engineers show you their Cato favorites. Dive in with them as they demonstrate how to set bidirectional quality of service, utilize Catos Zero Trust Network Access (ZTNA) capabilities, and deep dive into bandwidth management and analytics.
Slow build times and inefficiencies in packaging and distributing execution files were costing our ML/AI engineers a significant amount of time while working on our training stack. This P2P network enables direct content fetching from other CAS daemon instances, significantly reducing latency and storage bandwidth capacity.
More than anything, reliability becomes the principal challenge for network engineers working in and with the cloud. Even the most detailed reliability engineering can be easily undermined in an insecure network. While there is much to be said about cloud costs and performance , I want to focus this article primarily on reliability.
With so many network boundaries being navigated (application, service, cloud providers, subnets, SD-WANs , etc.), network operators and engineers cast as wide a net as possible to source their telemetry. With the level of detail that application-level telemetry provides, operators can quickly answer: Is this even a network problem?
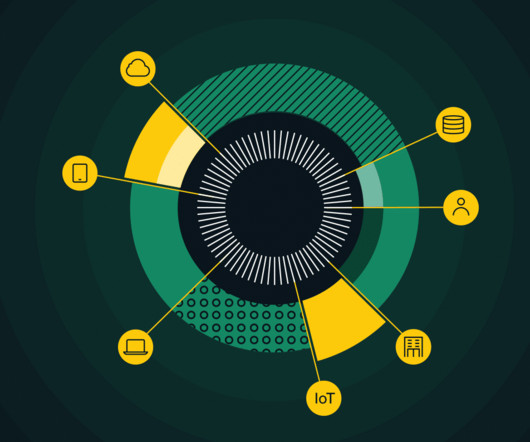
Networking and bandwidth play an important role in ensuring the clusters’ performance. Our systems consist of a tightly integrated HPC compute system and an isolated high-bandwidth compute network that connects all our GPUs and domain-specific accelerators. Building AI clusters requires more than just GPUs.
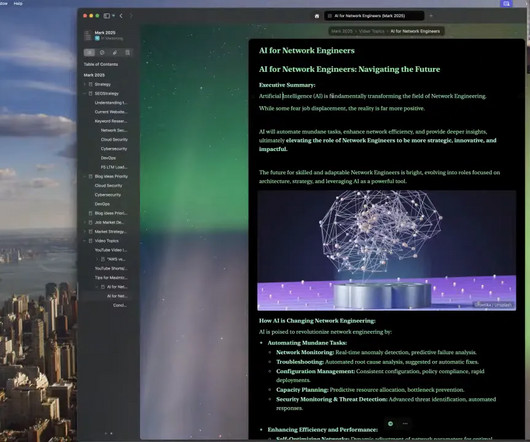
In the ever-evolving landscape of technology, AI For Network Engineers is reshaping how we approach network management. Rather than fearing job displacement, network engineers can embrace AI as a transformative tool that automates mundane tasks and enhances efficiency, ultimately leading to more strategic roles within organizations.
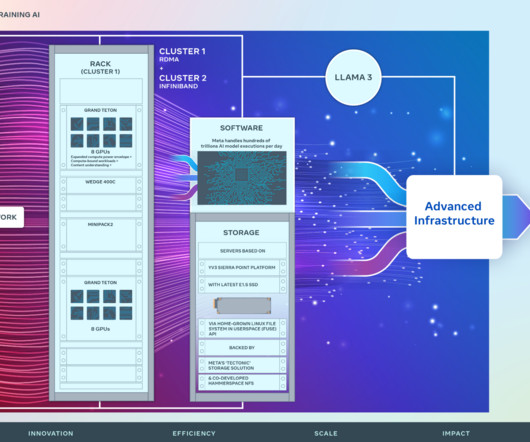
It played and continues to play an important role in the development of Llama and Llama 2 , as well as advanced AI models for applications ranging from computer vision, NLP, and speech recognition, to image generation , and even coding. The post Building Meta’s GenAI Infrastructure appeared first on Engineering at Meta.
But if we look at real-time communication (RTC) applications, while the video quality also has improved over time, it has always lagged behind that of camera quality. Improving video quality for low-bandwidth networks This post is going to focus on peer-to-peer (P2P, or 1:1) calls, which involve two participants.
Instrumenting business, application, and operational context to network telemetry give operators multifaceted views of traffic and behavior. Rich context and real-time datasets allow network engineers to dynamically filter, drill down, and map networks as queries adjust. Have full data context. Ask any questions about their network.
At the same time, the burdens of network downtime, slow troubleshooting, siloed architecture, and manual deployment make enterprise networks increasingly difficult to manage, especially when the demand to scale sites, add more devices and applications, and support Wi-Fi 6E/7 is on a sharp rise.
Yes, there’s something to say about how applications are written, but on the public internet side, we’ve seen a decrease in latency, cost, and a massive increase in available bandwidth. So what does this mean for today’s enterprise network engineer? This coincided with the advent of the public cloud like AWS, Azure, GCP, etc.
A recent study why Netscout surprised me that many engineers are aware of overload bandwidth or routing devices but give less considerations to state exhaustion in application aware devices. Its not widely that DDOS attacks also cause damage from state exhaustion in devices.
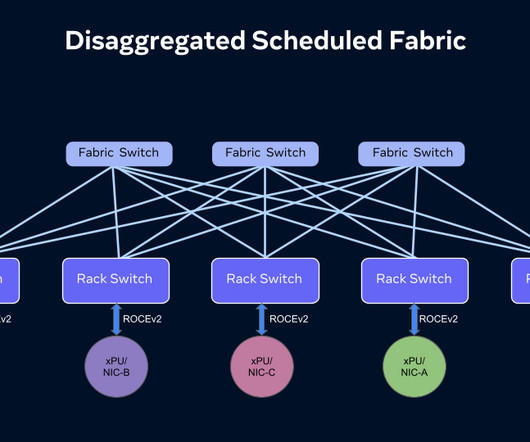
Now, through OCP, we’re bringing new open advanced network technologies to our data centers, and the wider industry, for advanced AI applications. DSF-based fabrics allow us to build large, non-blocking fabrics to support high-bandwidth AI clusters. We have collaborated with vendors, and the OCP community, to evolve SAI.
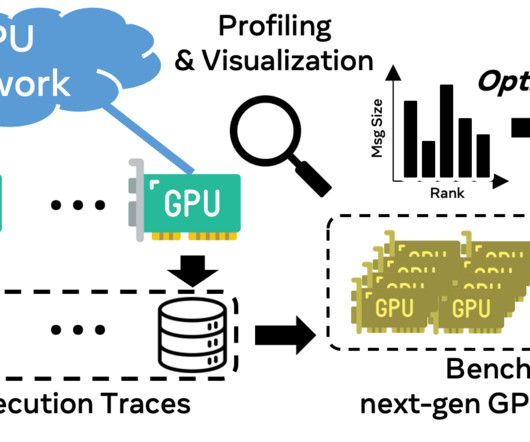
However, traditional full workload benchmarking presents several challenges: Difficulty in forecasting future system performance : When designing an AI system, engineers frequently face the challenge of predicting the performance of future systems. Our visualization tool can precisely highlight these imbalances, as shown by the below figure.
As people create, share, and consume an ever-increasing volume of online videos, Meta is working to develop the most bandwidth-efficient ways to transcode content while maintaining reasonable compute and power consumption levels. As a result, people who use our products can enjoy high-quality video at much lower bandwidth.
The concept of observability has taken hold in the DevOps, SRE and application performance monitoring (APM) space. The term has a literal engineering definition, that, in a nutshell, means the internal state of any system is knowable solely by external observation. Why is my bandwidth bill so high?
CCNA Interview Questions The CCNA certification serves as a foundational credential for network engineers. The layers include Physical, Data Link, Network, Transport, Session, Presentation, and Application. QoS ensures that critical applications receive the necessary bandwidth by prioritizing traffic.
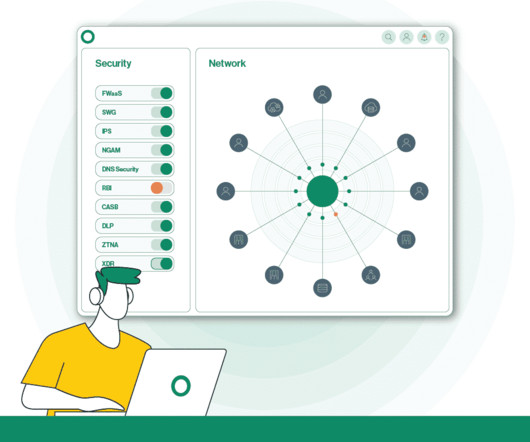
In this article, we will discuss some of the various policy objects that exist within the Cato Management Application and how they are used. Understanding Catos Management Application from Its Architecture To understand policy design within the Cato Management application, its useful to discuss some of Catos architecture.
Not only that, but it could also be received by a risk evaluation service, by Kafka Connect that will write the update to the profile database and perhaps by a real-time event streaming application that updates a dashboard showing the number of customers in each sales region. Schemas and APIs are contracts between services. Couldn’t you tell?”
To address this issue, the cryptography community has been working on a new class of cryptosystems known as post-quantum cryptography (PQC), which are expected to withstand quantum attacks but can be less efficient (in particular, communication bandwidth wise) than its classical counterparts.
SNMP data is also used by network engineers to troubleshoot reported problems along with network architects to do things like capacity planning. This could mean finding an application or network owner or blocking malicious traffic, such as a DDoS. Flow can also be used to understand consumption of bandwidth in a more granular manner.
And on top of all that, we need something that can deliver this data for as many applications as necessary, in real time, concurrently and reliably. The startup selected to build Genesis on the cloud had explained how hard refactoring an application to run in another cloud provider is when the code is written to run in a specific one.
SNMP data is also used by network engineers to troubleshoot reported problems along with network architects to do things like capacity planning. This could mean finding an application or network owner or blocking malicious traffic, such as a DDoS. Flow can also be used to understand consumption of bandwidth in a more granular manner.
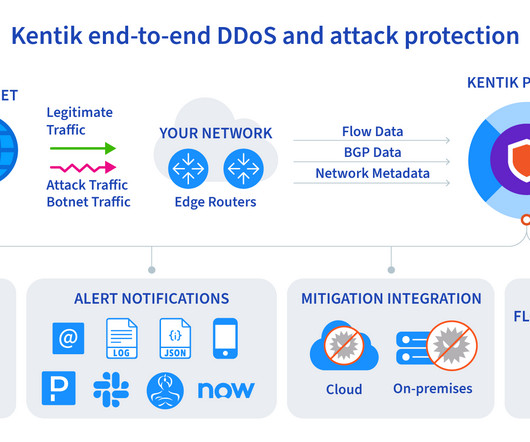
Distributed denial of service (DDoS) DDoS attacks are cyber attacks that most often have the purpose of causing application downtime. These attacks aim to overwhelm a service’s bandwidth capabilities with prohibitively high traffic volumes. Application layer. Application layer. Protocol-based.
This blog post goes over: The complexities that users will run into when self-managing Apache Kafka on the cloud and how users can benefit from building event streaming applications with a fully managed service for Apache Kafka. Key characteristics of a fully managed service that you can trust for production and mission-critical applications.
By making them readily available and building to scale, we can drive adoption of state-of-the-art reliably and put them in the hands of ML Engineers for rapidly building performant models across thecompany. This worked well with tree based models, however in the future, serving embeddings directly with DNN models can add up costs.
The Need for Speed The rapidly evolving technology and digital transformation landscape has ushered in increased requirements for high-speed connectivity to accommodate high-bandwidthapplication and service demands. This is significant because the single-pass cloud engine (SPACE) powers the platform.
The lack of a global, SLA-backed backbone leaves SD-WANs unable to provide the consistent, predictable transport needed by real-time service and business-critical applications. As a result, SD-WAN adopters have remained chained to their MPLS services, paying exorbitant bandwidth fees just to deliver these core applications.
SASE reduces the risk of cybersecurity breaches and enables global access to applications and systems. Main benefits include: Global connectivity: SASE provides the ability to securely connect tens of thousands of employees across dozens of plants around the globe to SaaS and on-premises applications.
The Dutch engineering company had built a global wide area network (WAN) out of MPLS and Internet services connecting 17 locations 14 in Europe and 3 in the Asia Pacific with about 800 mobile and field employees. Cloud applications were starved for bandwidth as they were backhauled across a 10 Mbits/s connection to the datacenter.
Theyre ready to realize the benefits of a new SASE infrastructure but remain constrained by their old beliefs about network engineering. Its a lot of time spent driving multiple CLIs to produce an outcome which is highly resistant to contemporary concepts of application classification, identity awareness, flexibility and visibility.
SD-WANs reduce bandwidth costs, no doubt, but enterprises are still left having to address important issues around cloud, mobility, and security. The Problem of MPLS Bandwidth costs remain the most obvious problem facing MPLS services. Bandwidth upgrades and changes can also take weeks. SD-WANs automate these and other steps.
Bandwidth utilization at various points in the network. By performing this type of network profiling, operators are able to understand the maximum capability of current resources and the impact of adding incremental new resources needed to serve future bandwidth demand and requirements. Capacity of current network infrastructure.
They also view the DIY approach as more cost-effective and as an opportunity to leverage the strengths of their internal engineering team. This shift impacts the use of MPLS , with the internet is being leveraged more often to boost overall bandwidth. The most critical SD-WAN features are hybrid connectivity, i.e
Simultaneously, we were also rapidly developing new features and use cases for DashPass, so the developer bandwidth for performance tuning was low. Alternatively, the cache could be invalidated directly within the application code when data changes. key: Instance of CacheKey. fallback: Invoked on a cache miss.
A recent conversation with a WAN engineer got me thinking about how network optimization techniques have changed over the years. Optimization has always been about overcoming latency, jitter, packet loss, and bandwidth limitations. However, in recent years bandwidth has become much less of an issue for most enterprises.
Those stakeholders can include members of management, security analysts, network engineers, application owners, and even your external partners (MSPs, VoIP, ISPs, etc.). Cato implements the SentinelOne Next-Gen Anti-Malware engine to provide a second layer of threat protection.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


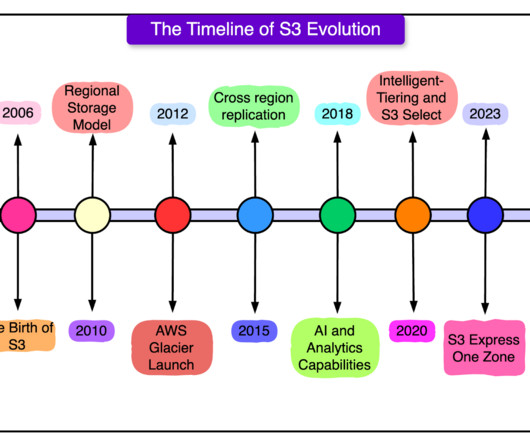

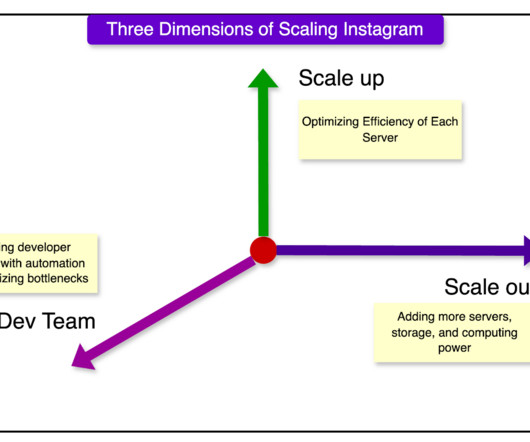
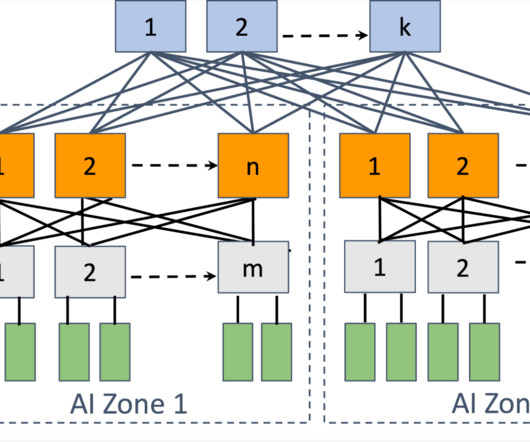

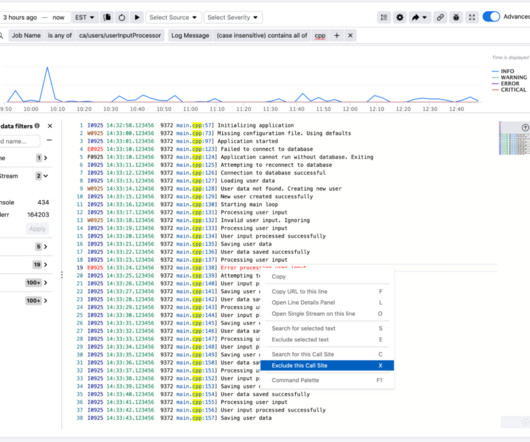




























Let's personalize your content